Jobs
Jobs are batch processing tasks that can be executed in various formats, including JAR files, Raw Scala, SQL, or Python3.
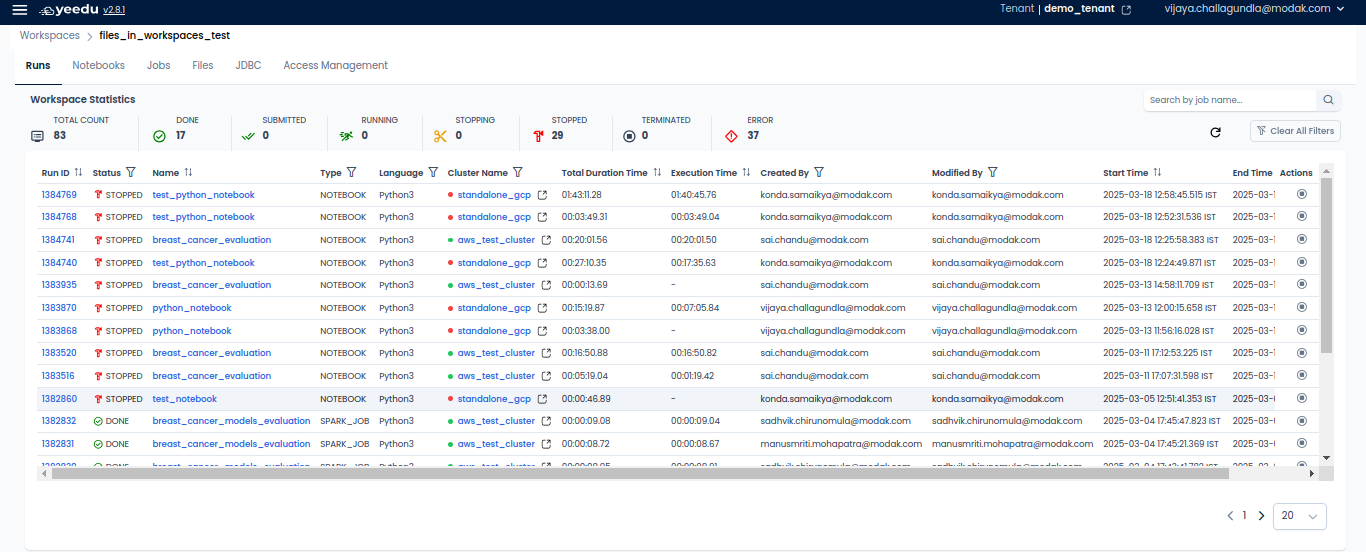
- Job ID: Displays the unique job ID linked to each job.
- Name: Shows the name of all the jobs present in the workspace.
- Type: Indicates the type of job, which can be Jar, Python3, Raw Scala, or SQL.
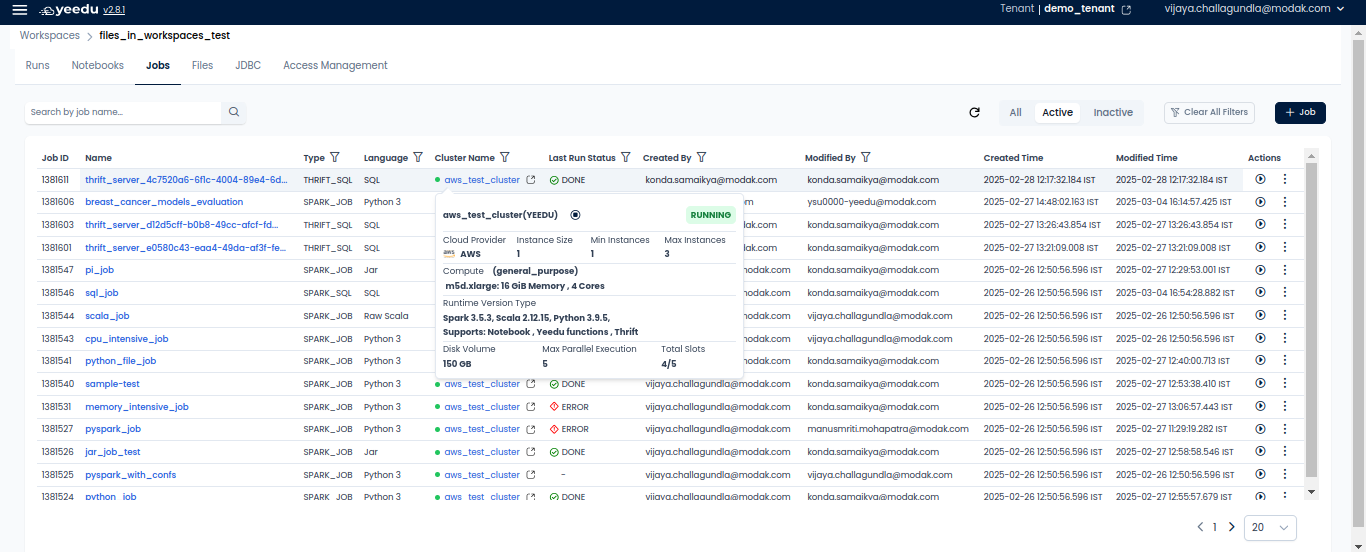
- Cluster Name: Showcases the name of the cluster associated with the job. Hovering over the cluster name reveals general configurations of the cluster.
- JDBC: For detailed information on JDBC, please click on Setting Up Thrift Server for Yeedu
- Last Run Status: Displays the last run status of the jobs, which can be Done, Stopped, or Error.
- Created By: Shows the name of the user who created the job.
- Modified By: Indicates the name of the user who last modified the job.
- Created Time: Displays the date and time of creation of a job.
- Modified Time: Indicates the date and time when the job was last modified.
- Action Tab: Allows users to perform two actions:
- Run: Executes the job.
- Disable: Enables users to disable the job. Once a job is disabled, it cannot be re-enabled; users must create a new job.
Manage
Create Jobs
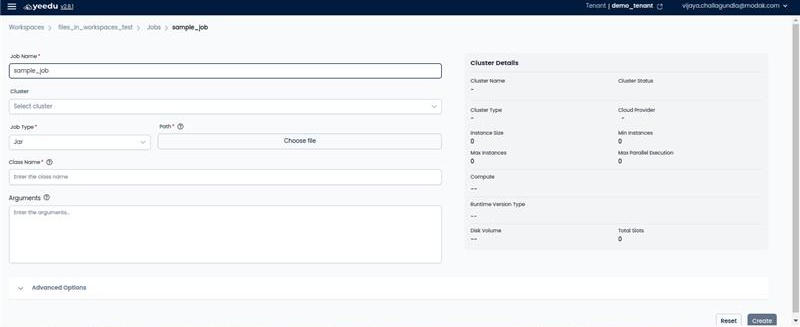
On the right side of the job dashboard, users can find the '+ Job' icon located above the Action tab. Upon clicking the '+ Job' button, users will be redirected to the New Job window.
- Job Name: Input the name of the job in this field, ensuring it meets the following prerequisites:
- Maximum length: 64 characters
- Lowercase letters
- Permitted symbols: '-', '_', '@', and '.'
- Cluster: Select the cluster assigned to the workspace that best fits your requirements.
- Job Type: Depending on the use case, select one of the four job types:
- Jar: Allows users to add details in the Class Name and Argument fields.
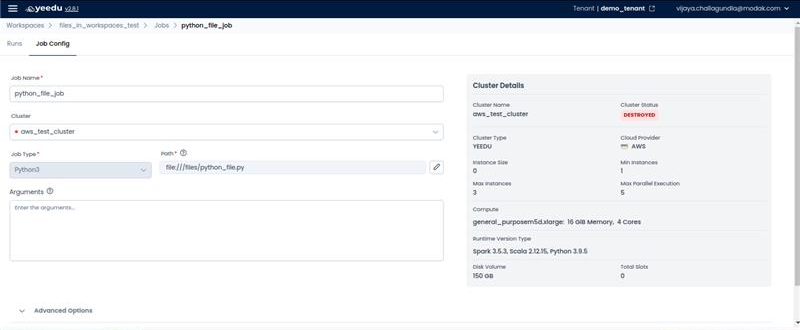
- Python3: Provides only the Argument field.
- Raw Scala: Offers the option to manually input raw Scala code or upload the code.
- SQL: Provides options to manually input SQL queries or upload the queries.
- Path: Contains the path to commands or executables that specify the job to be run. The path is managed in 'Dependency Repositories'.
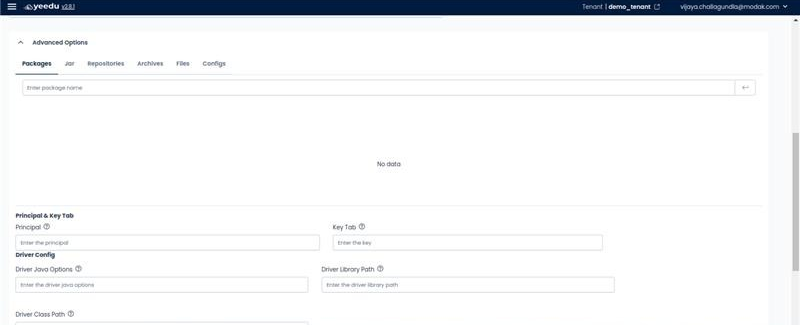
- Advanced Options: Add additional configurations to the job such as packages, JARs, repositories, archives, files, configs, driver configs, and concurrent runs.
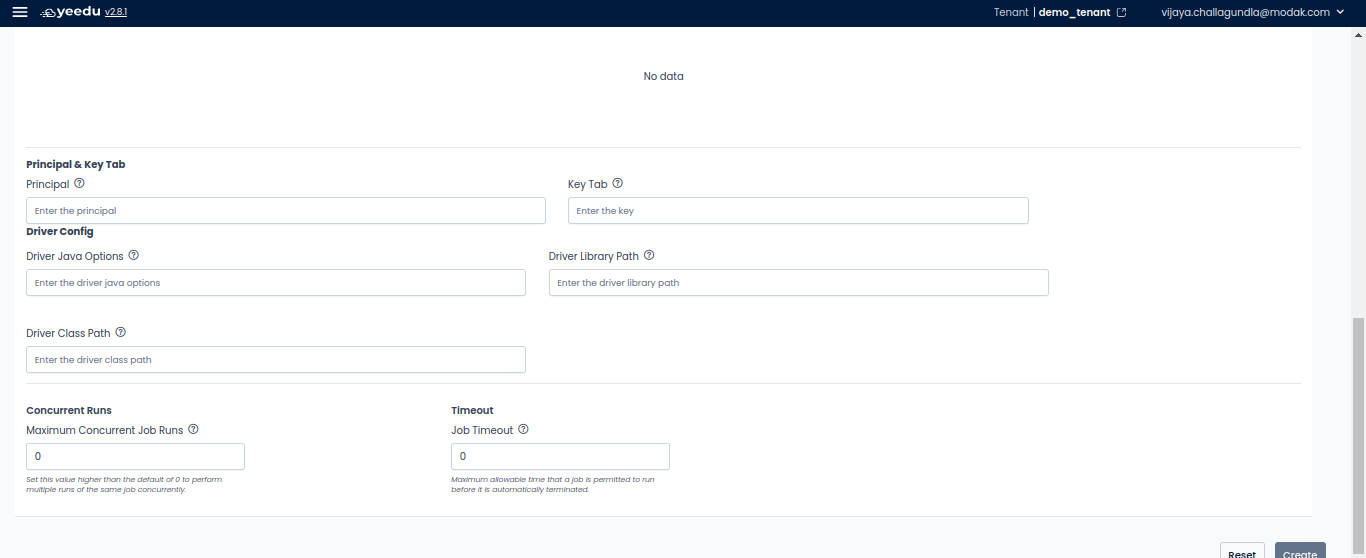
Modify Jobs
The Job window comprises two sections:
- Runs: Presents details of the job runs including Run ID, Status, Type, Cluster Name, Duration, Created By, Modified By, Start Time, End Time, and an Action Button (to stop the job while it is in the executing or running state). Users also have the option to run the job from this view.
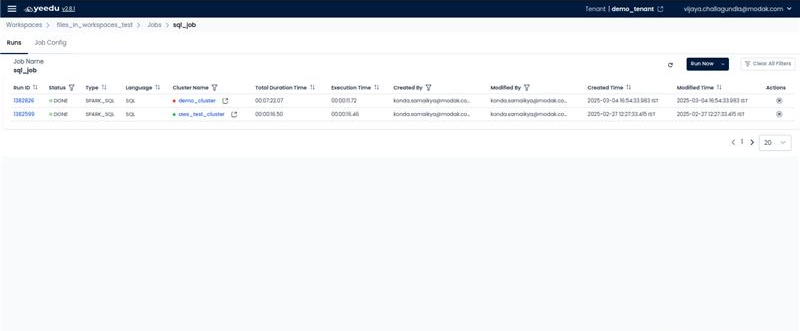
- Job Config: Enables users to modify or make changes in the configurations of the job. Users can alter all configurations except for the Job Type.
Job Types
Yeedu consists of six job types: JAR,Raw Scala, Python3, SQL, Thrift SQL, and Yeedu Functions.
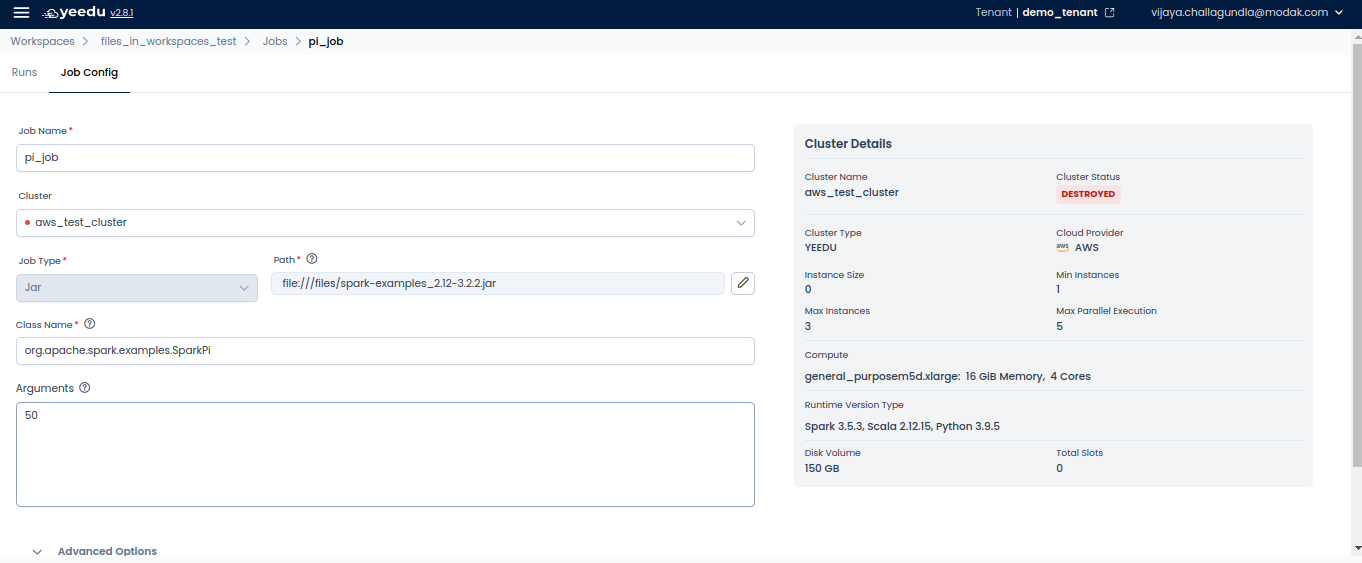
- Jar – Executes a JAR file, typically for Java-based Spark applications, requiring a class name and optional arguments.
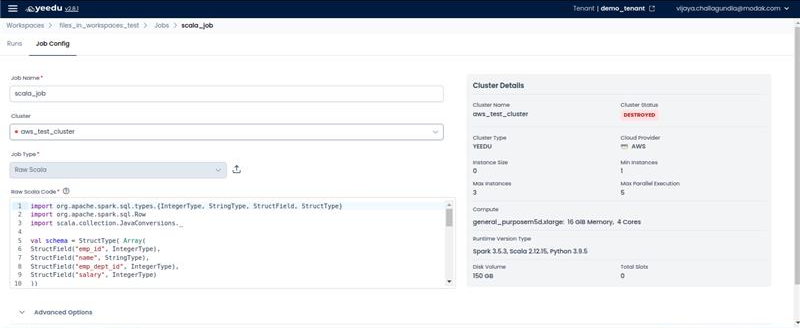
- Raw Scala – Runs Scala code directly within the job configuration, ideal for Spark-based computations.
- SQL – Processes SQL queries on structured data, commonly used for analytics and data transformations.
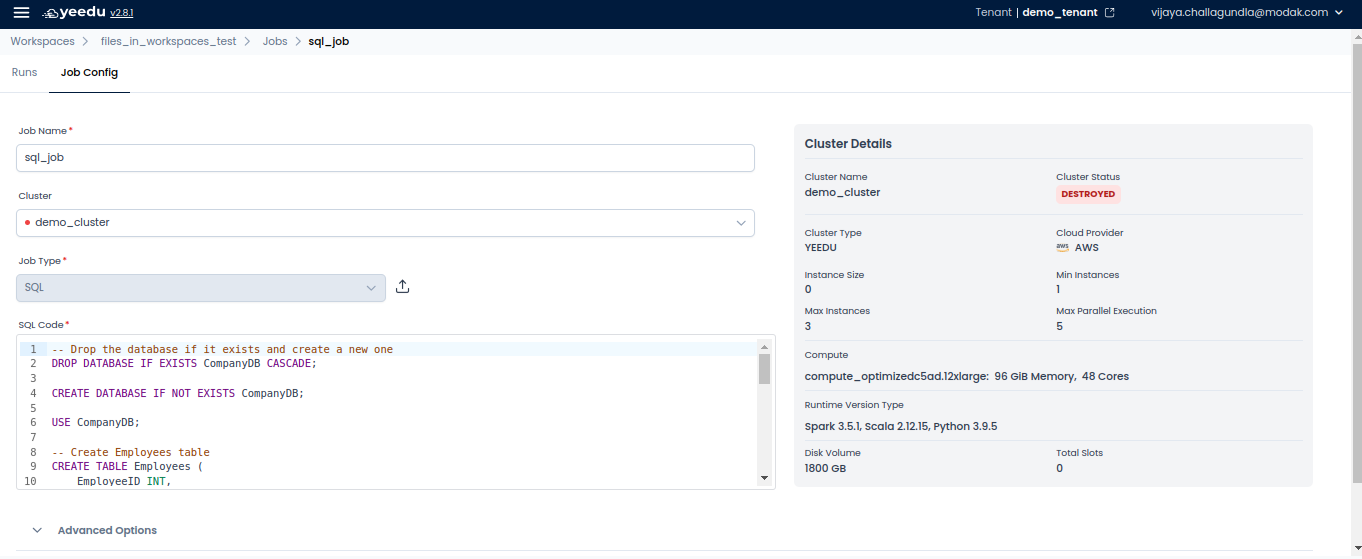
- Python3 – Runs Python scripts, enabling users to execute Spark jobs or standalone Python programs.
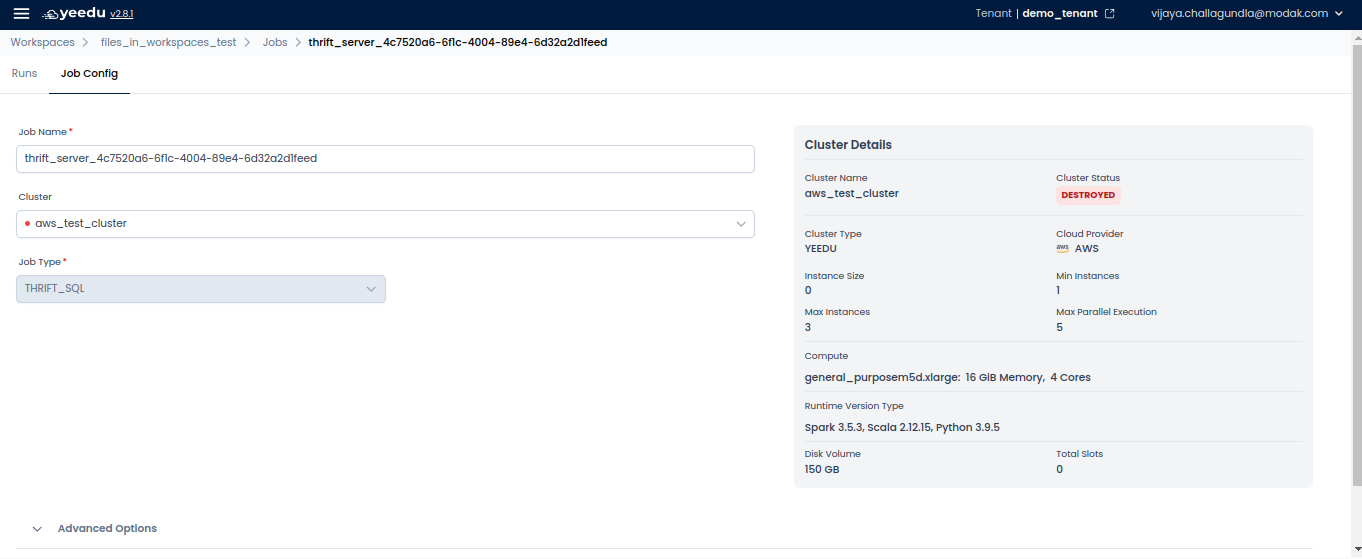
- Thrift SQL – Utilizes Apache Thrift to execute SQL commands on a database or distributed data system.
- Yeedu Functions – Enabling users to execute jobs using APIs as function parameters. These functions operate in a fully managed environment, scale automatically, and execute based on triggers or events.
Accessing Yeedu Functions
- Navigate to the Workspaces section.
- Under the Jobs tab, locate and select the desired job.
Configuring a Function
To set up a function, configure the following fields:
Job Configuration
-
Job Type: Select Yeedu Function from the dropdown.
-
Cluster: Choose a cluster to run the job.
-
Project Path: Select the appropriate project folder.
-
Function Name: Enter the function name.
-
Script Path: Choose the files required for the function execution.
-
Function URL: This is the REST API endpoint to trigger the function.
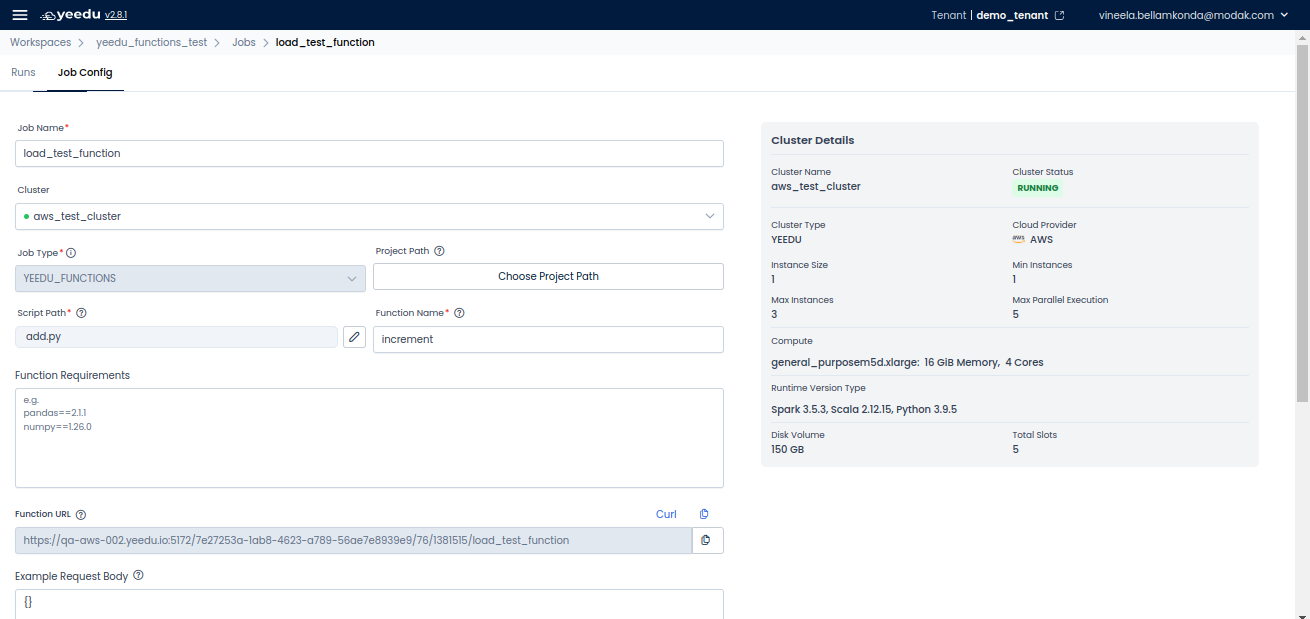
Function Requirements
-
Define required Python packages.
-
Specify the request body payload containing parameters to execute the output.
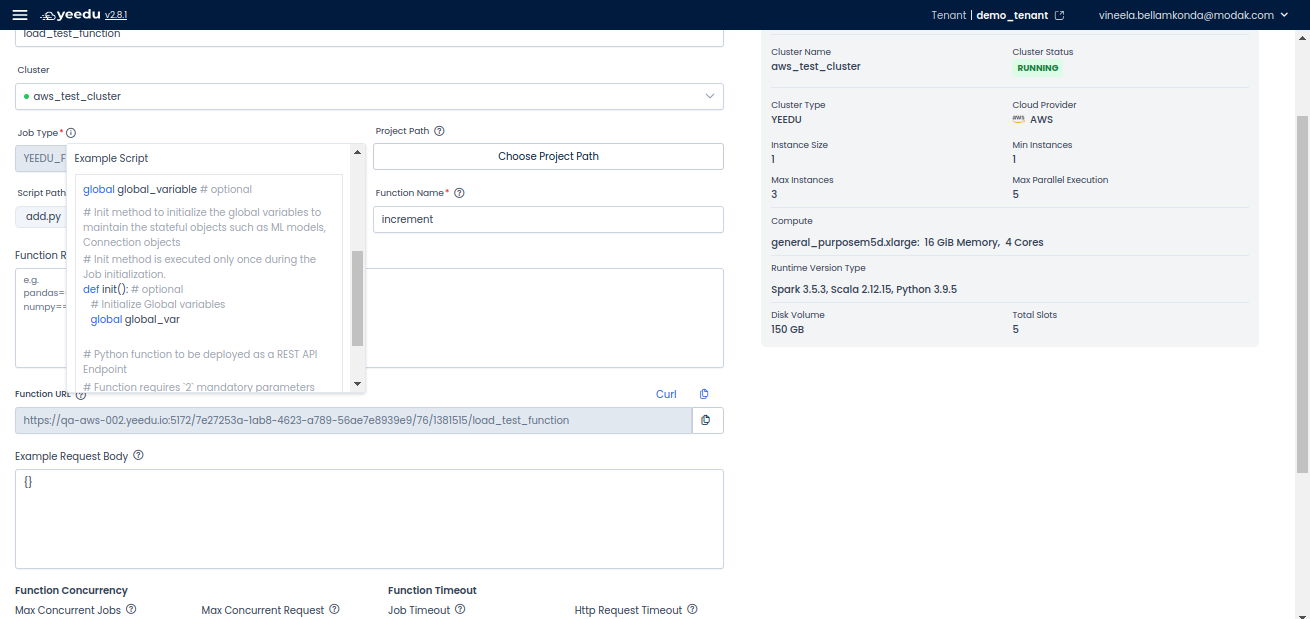
Function Concurrency & Timeout Settings
- Max Concurrent Jobs: Set a value higher than 0 to allow multiple runs.
- Max Concurrent Requests: Define the number of API requests.
- Job Timeout: Set the maximum allowable idle time in seconds before termination.
- HTTP Request Timeout: Define the maximum time (in seconds) to wait for a response.
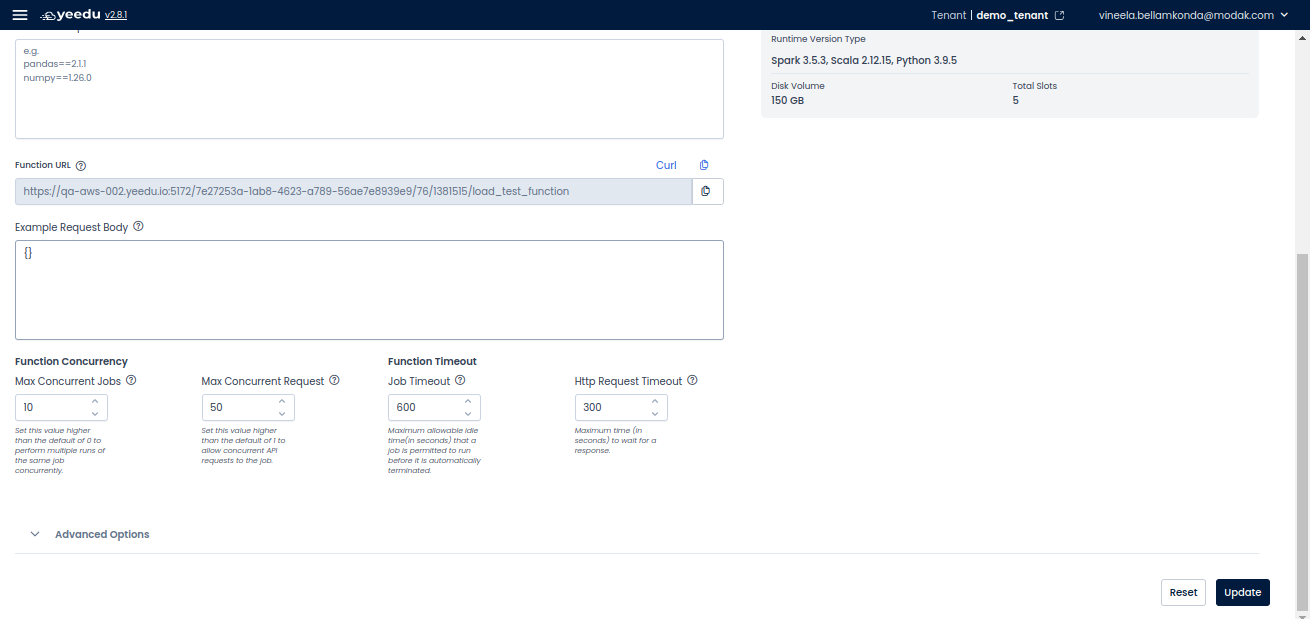
Executing a Function
- Configure the function settings as required.
- Click on Update to save changes.
- Use the Function URL to trigger the function via API requests.
The recommended resolution for Yeedu UI is 1920 x 1080.