Disaster Recovery Strategy
Disaster Recovery Strategy Introduction
Yeedu is a cutting-edge data processing and orchestration platform designed to handle modern workloads with a focus on reliability, resilience, and scalability. This document provides a detailed overview of Yeedu's Disaster Recovery (DR) strategy, which ensures uninterrupted services and data integrity during unforeseen disasters. The strategy is optimized for cloud-native deployments on Kubernetes across major cloud providers, including AWS, GCP, and Azure.
Overview
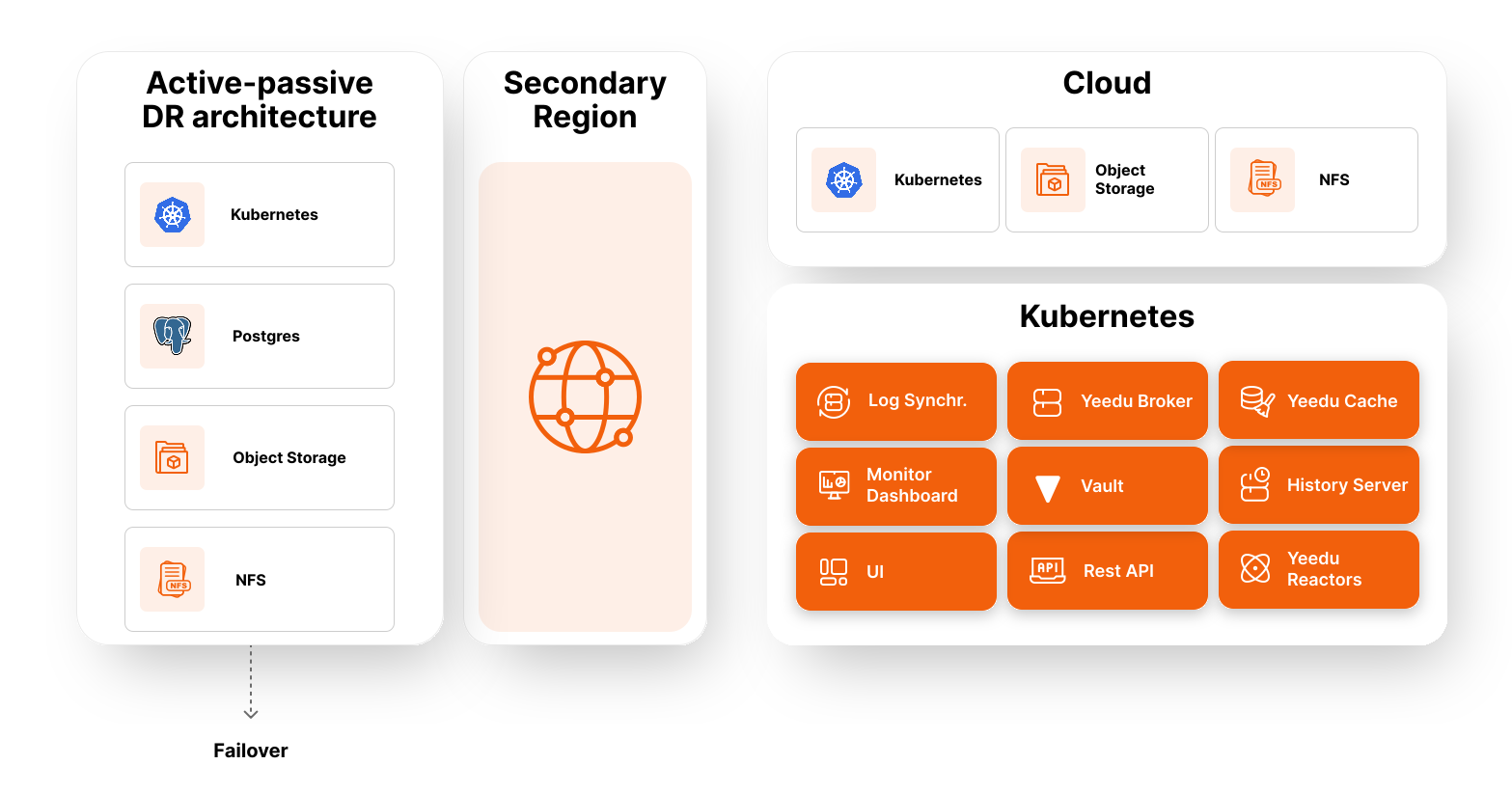
Disaster Recovery (DR) is a critical component of Yeedu's architecture. The platform employs an Active-Passive DR model to ensure service continuity during disasters. This model involves deploying services across multiple cloud regions, with one region (primary) actively serving requests and another region (secondary) remaining dormant until a disaster occurs.
Key principles of Yeedu's DR strategy include:
- Data Independence: Yeedu does not store user data. Instead, it processes data from user-configured sources and destinations, ensuring no risk to data integrity.
- Cloud-Native Deployments: All Yeedu services are orchestrated using Kubernetes, leveraging its scalability and resilience.
- Cloud-Managed Services: Critical components like PostgreSQL, Object Storage, and NFS are configured for geo-redundancy to minimize downtime.
Active-Passive Strategy
Primary and Secondary Regions
- Primary Region (Active): The primary region (e.g.,
us-central) hosts all active services and handles user requests. - Secondary Region (Passive): The secondary region (e.g.,
us-east) has resources deployed but kept inactive to reduce costs. These resources are activated only during a disaster.
Steps During Disaster
In the event of a disaster in the primary region, the following steps are executed:
- Activate Passive Resources: Start cloud services (e.g., PostgreSQL, Object Storage, NFS) and the Kubernetes cluster in the secondary region.
- Restore Data: If data replication is not automatic, restore data from backups.
- Deploy Yeedu Services: Deploy all Yeedu services on the secondary Kubernetes cluster.
- Resume Operations: Services resume on the same domain (e.g.,
dev.yeedu.io), ensuring minimal disruption.
Components for DR
| Category | Components | DR Config Required |
|---|---|---|
| Cloud | PostgreSQL, Object Storage, NFS, Kubernetes | Yes |
| Internal | Broker, Cache, UI, API, Vault, Reactors, History Server, Dashboard | Deployed via Kubernetes |
Active-Active Strategy
In an Active-Active DR model, resources in both regions are always active. This approach significantly reduces recovery time but comes with higher operational costs due to the continuous operation of resources in both regions.
Pros and Cons of Active-Active vs. Active-Passive
Active-Active
Pros:
- Minimal Downtime: Failover is almost instantaneous, with an RTO of approximately 5 minutes.
- Load Balancing: Traffic can be distributed across both regions, improving performance and reducing latency.
- High Resilience: Both regions are fully operational, reducing the risk of a single point of failure.
- No Manual Activation: Resources are already active, eliminating the need for manual intervention during failover.
Cons:
- Higher Costs: Resources in both regions are always active, leading to increased operational expenses.
- Complexity: Requires sophisticated configuration and monitoring to ensure consistency between regions.
- Data Synchronization: Continuous synchronization of data between regions can be challenging and resource-intensive.
Active-Passive
Pros:
- Cost-Effective: Resources in the secondary region are kept inactive, reducing operational costs.
- Simpler Configuration: Easier to manage since only one region is active at a time.
- Controlled Failover: Failover is a deliberate process, allowing for better planning and execution.
Cons:
- Longer Downtime: Requires manual activation of resources in the secondary region, leading to an RTO of approximately 25 minutes.
- Risk of Delayed Recovery: If the failover process encounters issues, recovery time may increase.
- Underutilized Resources: The secondary region remains idle until a disaster occurs, leading to resource inefficiency.
Typical Recovery Workflow
A typical disaster recovery scenario for Yeedu involves the following steps:
- Failure Detection: A failure occurs in a critical service in the primary region. This could be a failure in a data source, network, or cloud infrastructure impacting the Yeedu deployment.
- Investigation: The issue is investigated with the cloud provider to determine the scope and expected resolution time.
- Decision to Failover: If the issue cannot be resolved promptly, a decision is made to failover to the secondary region.
- Verification: Ensure that the same issue does not impact the secondary region.
- Failover Execution:
- Stop all activities in the primary region. Users stop workloads, and administrators back up recent changes if possible.
- Shut down jobs that have not already failed due to the outage.
- Start the recovery procedure in the secondary region. This includes updating routing and renaming connections to redirect traffic to the secondary region.
- Testing and Declaration: After testing, declare the secondary region operational. Users can resume workloads, and delayed jobs can be retriggered.
- Failback to Primary Region:
- Once the issue in the primary region is resolved, stop all activities in the secondary region.
- Start the recovery procedure in the primary region, including routing and renaming connections back to the primary region.
- Replicate data back to the primary region as needed. Minimize replication complexity by focusing on critical data.
- Test the deployment in the primary region and declare it operational.
What Needs to Be Backed Up and Restored
What Needs to Be Backed Up
- Database (PostgreSQL):
- Regular backups of the database are essential to ensure data consistency.
- Use cloud-managed database services with geo-redundancy or scheduled backups.
- Object Storage:
- Backup critical files and data stored in object storage.
- Enable versioning and replication across regions.
- NFS (Network File System):
- Backup shared file systems used by Yeedu services.
- Use cloud-native solutions like AWS EFS, GCP Filestore, or Azure Files with cross-region replication.
- Configuration Files:
- Backup Kubernetes manifests, Helm charts, and other deployment configurations.
- Include
spark-defaults.conf,spark-env.sh, and other service-specific configurations.
- Application State:
- Backup stateful data for services like Yeedu Cache, Broker, and Vault.
- Ensure logs and metadata are included for debugging and auditing.
What Needs to Be Restored
- Database (PostgreSQL):
- Restore the latest backup or use the replicated database in the secondary region.
- Ensure all transactions up to the point of failure are applied.
- Object Storage:
- Restore critical files and data to the secondary region.
- Validate the integrity of the restored data.
- NFS:
- Mount the replicated or restored file system in the secondary region.
- Ensure all services dependent on NFS can access the required files.
- Configuration Files:
- Deploy the backed-up Kubernetes manifests and configurations in the secondary region.
- Update any region-specific settings (e.g., DNS, IP addresses).
- Application State:
- Restore the stateful data for services like Yeedu Cache, Broker, and Vault.
- Ensure services are fully operational and consistent with the primary region.
Recovery Objectives
Recovery Point Objective (RPO)
The Recovery Point Objective (RPO) defines the maximum acceptable amount of data loss measured in time. For Yeedu, the RPO depends on the frequency of data replication between the primary and secondary regions. With proper configuration, the RPO can be as low as a few seconds or minutes.
Recovery Time Objective (RTO)
The Recovery Time Objective (RTO) defines the maximum acceptable time to restore services after a disaster. For Yeedu:
- Active-Passive RTO: Approximately 25 minutes, including the time to activate resources, restore data, and deploy services.
- Active-Active RTO: Approximately 5 minutes, as resources in both regions are already active.
Timelines for Recovery
The time required to recover from a disaster depends on the DR model used. The table below outlines the estimated recovery times:
| Step | Active-Passive Time | Active-Active Time |
|---|---|---|
| Start Cloud Services (Postgres, NFS, Object Storage) | 12–15 mins | N/A |
| Start Kubernetes Cluster | 5 mins | N/A |
| Deploy Yeedu Services | 5 mins | N/A |
| Total Recovery Time | ~25 mins | ~5 mins |
Conclusion
Yeedu's Disaster Recovery strategy is designed to provide a robust and scalable solution for handling disasters. By leveraging cloud-native services, Kubernetes orchestration, and a well-defined Active-Passive model, Yeedu ensures:
- Rapid failover during region-wide outages.
- Minimal downtime with clear recovery timelines.
- Cost-effective disaster recovery solutions tailored to modern workloads.
Implementing this strategy will ensure your Yeedu deployments remain resilient, reliable, and ready to handle any disaster scenario.