Yeedu High Availability
Yeedu High Availability Introduction
High Availability (HA) is a cornerstone of Yeedu’s architecture, ensuring uninterrupted service, fault tolerance, and operational resilience. This document outlines how Yeedu leverages cloud-native infrastructure, Kubernetes orchestration, and service-level redundancy to deliver enterprise-grade HA across all core components.
Overview
Yeedu is designed from the ground up with high availability in mind. All cloud and internal components are structured to maintain service continuity, enable automatic recovery, and deliver optimal performance during peak loads or unexpected failures.
Recovery Objectives
Recovery Time Objective (RTO)
Yeedu’s services are engineered to achieve an RTO of < 5 minutes for core services. Most services are configured with auto-healing policies that restart or replace failed pods in 2 to 5 seconds, ensuring near-zero downtime.
Recovery Point Objective (RPO)
Yeedu targets an RPO of ≤ 10 seconds for critical data, thanks to its continuous log synchronization and frequent cache replication mechanisms.
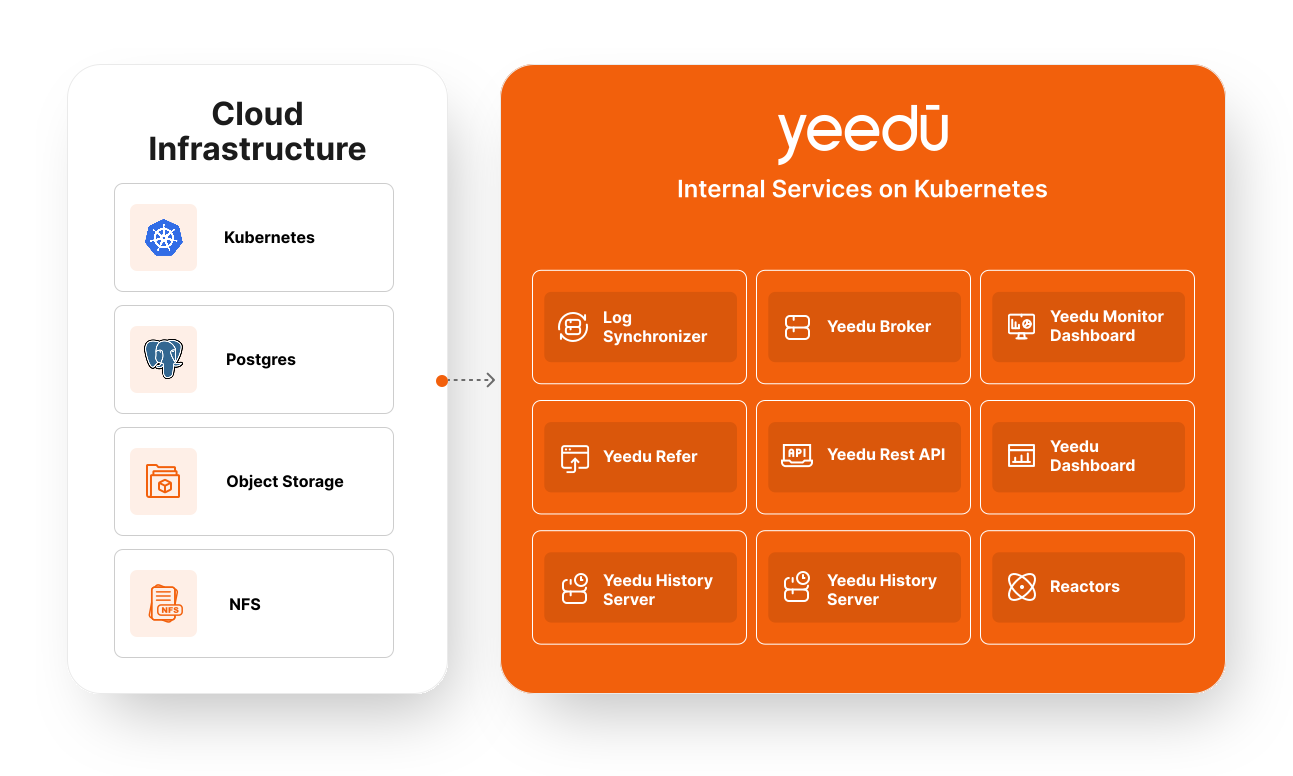
Cloud Infrastructure Components
The foundational cloud infrastructure components that enable high availability for Yeedu services include:
| Service | Description | HA Strategy |
|---|---|---|
| Postgres | Primary backend database | Uses 2 databases for high availability and failover. |
| Object Storage | Persistent data lake for logs and jobs | Uses cloud-native HA object store. |
| NFS | Shared file system across services | Mounted via HA-enabled network drives. |
| Kubernetes | Cloud-hosted orchestration engine. All Yeedu services run on Kubernetes. | Built-in self-healing, auto-scaling, probing. |
Each of these components is set up in the cloud with high availability features enabled during resource provisioning.
Core Yeedu Internal Services
Yeedu’s high availability and distributed architecture are powered by the following key internal service components:
1. Log Synchronizer
- Purpose: Synchronizes application and platform logs to Object Storage every 10 seconds.
- HA Mechanism:
- Kubernetes Liveness and Readiness probes ensure service health.
- On failure, a new replica is spun up within 2–5 seconds, minimizing downtime.
- Horizontal Pod Autoscaling (HPA) ensures scalability during load surges.
- Replicas: Min: 1, Max: 1
- Init Time (Approx.): 3–5 seconds
2. Yeedu Broker
- Purpose: Coordinates distributed state and message flow.
- Architecture: Based on Raft consensus protocol (leader-election model).
- HA Mechanism:
- Seamless failover from leader to follower nodes.
- Automatic node recovery via healing policies.
- Resilience behavior similar to Kafka under node failures.
3. Yeedu Cache
- Purpose: High-speed data access layer.
- Architecture: Master-replica distributed model.
- HA Mechanism:
- Data replication across a minimum of 3 replicas.
- Ensures redundancy and availability of in-memory state.
4. Yeedu Monitor Dashboard
- Purpose: UI for system metrics and diagnostics.
- Backend: Postgres (HA-configured).
- HA Mechanism:
- Minimum of 3 dashboard service replicas, with autoscaling based on user activity.
- Relies on HA configuration of the Postgres DB.
- Replicas: Min: 1, Max: 1
- Init Time (Approx.): 3–5 seconds
5. Yeedu UI
- Purpose: End-user interface.
- HA Mechanism:
- Default minimum of 3 replicas, maximum of 5.
- Scales horizontally once CPU utilization reaches 65%.
- Kubernetes self-healing ensures prompt recovery in failure scenarios.
6. Yeedu REST API
- Purpose: Central API layer interfacing with Broker, Cache, Vault.
- HA Mechanism:
- Maintains 3–5 replicas via autoscaling.
- Scaling triggered on CPU threshold (65%).
- Readiness/liveness probes and self-healing ensure uninterrupted access.
- Replicas: Min: 1, Max: 3
- Init Time (Approx.): 3–5 seconds
7. Yeedu Vault
- Purpose: Secure secret management and storage.
- Backend: Postgres (HA-enabled).
- HA Mechanism:
- Inherits HA from Postgres backend.
- Ensures secrets are always available and accessible securely.
- Replicas: Min: 3, Max: 3
- Init Time (Approx.): 8–10 seconds
8. Yeedu History Server
- Purpose: Stores job and pipeline execution histories.
- Backend: Object Storage.
- HA Mechanism:
- Configurable with 1 to 3 replicas.
- Automatically scaled based on usage and data inflow.
- Replicas: Min: 1, Max: 1
- Init Time (Approx.): 3–5 seconds
9. Yeedu Reactors
- Purpose: Executes backend compute functions and jobs.
- Dependencies: Broker, Cache, Vault.
- HA Mechanism:
- Redundant replicas maintained.
- Scaling and recovery based on health checks and load patterns.
10. Yeedu Functions Scheduler
- Purpose: Schedules backend compute functions and jobs.
- HA Mechanism:
- Ensures redundancy through autoscaling.
- Scaling and recovery based on health checks and load patterns.
- Replicas: Min: 1, Max: 1
- Init Time (Approx.): 3–5 seconds
Kubernetes-Level HA Assurance
All Yeedu components are deployed within a Kubernetes Cluster, providing the following native HA capabilities:
- Liveness & Readiness Probes: Actively monitor service health and responsiveness.
- Pod Auto-Healing: Automatically restarts failed containers.
- Horizontal Pod Autoscaler (HPA): Dynamically adjusts replicas based on CPU/memory usage.
- State Management: Ensures the desired replica count is always maintained.
Final Kubernetes Component Configuration
Below is the configuration for final Kubernetes components in Yeedu:
| Component Name | Min Replicas | Max Replicas | Init Time (Approx.) |
|---|---|---|---|
| yeedu-rabbitmq3 | 3 | 3 | 1 minute |
| yeedu-ldap | 1 | 1 | 5 seconds |
| yeedu-redis | 1 | 1 | 10 seconds |
| yeedu-grafana | 1 | 1 | 3–5 seconds |
| yeedu-influxdb | 1 | 1 | 3–5 seconds |
| yeedu-reactors-cosi | 1 | 1 | 3–5 seconds |
| yeedu-reactors-monitor | 1 | 1 | 3–5 seconds |
| yeedu-restapi | 1 | 3 | 3–5 seconds |
| yeedu-reactors-log-sync | 1 | 1 | 3–5 seconds |
| yeedu-history-server | 1 | 1 | 3–5 seconds |
| yeedu-functions-scheduler | 1 | 1 | 3–5 seconds |
| yeedu-functions-celery | 2 | 2 | 3–5 seconds |
| yeedu-functions-proxy | 2 | 2 | 3–5 seconds |
| yeedu-vault | 3 | 3 | 8–10 seconds |
Recovery Timelines
The table below summarizes how each Yeedu component recovers automatically using HA mechanisms and their typical recovery times:
| Component | HA Mechanism | Recovery Time |
|---|---|---|
| Kubernetes Pods | Auto-restart via probes | 2–5 seconds |
| Log Synchronizer | Auto-restart + pod scaling | 2–5 seconds |
| Yeedu Broker | Raft-based leader failover | Immediate |
| Yeedu Cache | Master-replica fallback | 2–5 seconds |
| Monitor Dashboard | Autoscaled replicas + HA Postgres | 2–5 seconds |
| Yeedu UI | Autoscaling + self-healing | < 5 seconds |
| Yeedu REST API | Autoscaling + self-healing | < 5 seconds |
| Yeedu Vault | Backed by HA Postgres | Transparent |
| Yeedu History Server | Object Storage + scaled replicas | 2–5 seconds |
| Yeedu Reactors | Redundant replicas + health checks | 2–5 seconds |
| Postgres / Object Store / NFS | Cloud-native HA setup | Transparent |
Total Recovery Time: ~5 minutes or less across all services
Conclusion
Yeedu’s architecture leverages:
- Cloud-native HA infrastructure,
- Microservice redundancy,
- Kubernetes orchestration features,
- Consensus algorithms (Raft for Broker),
- Dynamic autoscaling policies.
This end-to-end approach ensures fault tolerance, scalability, and enterprise-grade availability for mission-critical deployments.